Gausssian-Mixture Regression (California Housing Data)¶
![]()
Mixture densities or mixture distributions offer an extension to the notion of traditional univariate distributions by allowing the observed data to be thought of as arising from multiple underlying processes. In its essence, a mixture distribution is a weighted combination of several component distributions, where each component contributes to the overall mixture distribution, with the weights indicating the importance of each component. For instance, if you imagine the observed data distribution having multiple modes, a mixture of Gaussians could be employed to capture each mode with a separate Gaussian distribution.
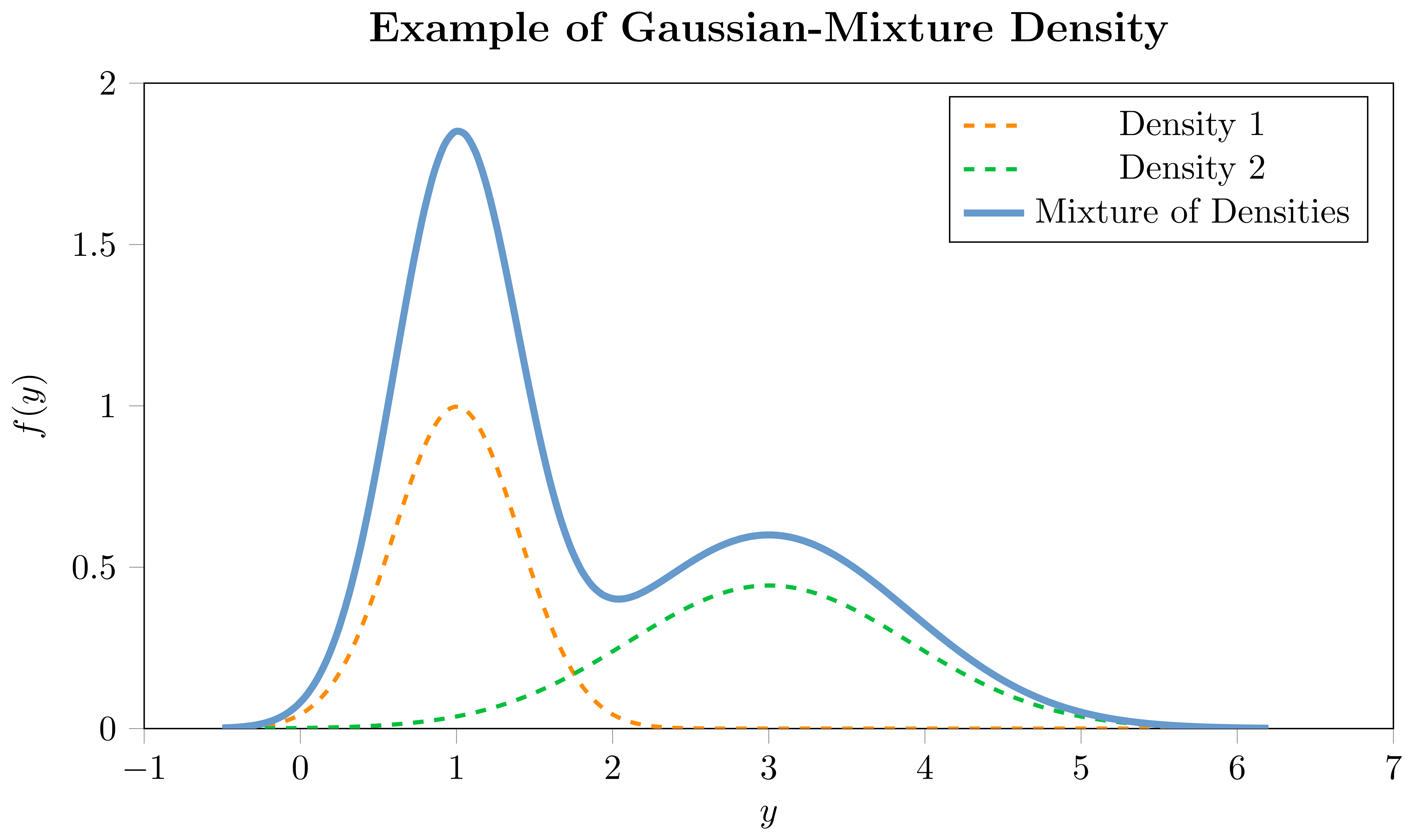
For each component of the mixture, there would be a set of parameters that depend on covariates, and additional mixing coefficients which are also modeled as a function of covariates. This is particularly useful when a single parametric distribution cannot adequately capture the underlying data generating process. A mixture distribution can be represented as follows:
\begin{equation} f\bigl(y_{i} | \boldsymbol{\theta}_{i}(x_{i})\bigr) = \sum_{m=1}^{M} w_{i,m}(x_{i}) \cdot f_{m}\bigl(y_{i} | \boldsymbol{\theta}_{i,m}(x_{i})\bigr) \end{equation}
where $f(\cdot)$ represents the mixture density for the $i$-th observation, $f_{m}(\cdot)$ is the $m$-th component density, each with its own set of parameters $\boldsymbol{\theta}_{i,m}(\cdot)$, and $w_{i,m}(\cdot)$ represent the weights of the $m$-th component in the mixture, subject to $\sum_{j=1}^{M} w_{i,m} = 1$. The components can either be a combination of different parametric univariate distributions, such as a combination of a Normal and a StudentT, or, as in our implementation, a combination of the same distribution-type with different parameterizations, e.g., Gaussian-Mixture or StudentT-Mixture. The choice of the component distributions depends on the characteristics of the data and the underlying assumptions. Due to their high flexibility, mixture densities can portray a diverse range of shapes, making them adaptable to a plethora of datasets.
Imports¶
from lightgbmlss.model import *
from lightgbmlss.distributions.Gaussian import *
from lightgbmlss.distributions.Mixture import *
from lightgbmlss.distributions.mixture_distribution_utils import MixtureDistributionClass
from sklearn import datasets
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import seaborn as sns
figure_size = (10,5)
import plotnine
from plotnine import *
plotnine.options.figure_size = figure_size
Data¶
housing_data = datasets.fetch_california_housing()
X, y = housing_data["data"], housing_data["target"]
feature_names = housing_data["feature_names"]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
dtrain = lgb.Dataset(X_train, label=y_train)
Distribution Selection¶
In the following, we specify a list of candidate distributions. The function dist_select returns the negative log-likelihood of each distribution for the target variable. The distribution with the lowest negative log-likelihood is selected. The function also plots the density of the target variable and the fitted density, using the best suitable distribution among the specified ones. However, note that choosing the best performing mixture-distribution based solely on training data may lead to overfitting, since mixture-densities can approximate any distribution arbitrarily well. It is therefore crucial to carefully select the specifications to strike a balance between model complexity and generalization ability.
mix_dist_class = MixtureDistributionClass()
candidate_distributions = [
Mixture(Gaussian(response_fn="softplus"), M = 2),
Mixture(Gaussian(response_fn="softplus"), M = 3),
Mixture(Gaussian(response_fn="softplus"), M = 4),
]
dist_nll = mix_dist_class.dist_select(target=y_train, candidate_distributions=candidate_distributions, max_iter=50, plot=True, figure_size=(8, 5))
dist_nll
Fitting of candidate distributions completed: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:05<00:00, 1.76s/it]

| nll | distribution | |
|---|---|---|
| rank | ||
| 1 | 13576.063477 | Mixture(Gaussian, tau=1.0, M=4) |
| 2 | 23268.498047 | Mixture(Gaussian, tau=1.0, M=3) |
| 3 | 23737.701172 | Mixture(Gaussian, tau=1.0, M=2) |
# Specifies a mixture of Gaussians. See ?Mixture for an overview.
lgblss = LightGBMLSS(
Mixture(
Gaussian(response_fn="softplus", stabilization="L2"),
M = 4,
tau=1.0,
hessian_mode="individual",
)
)
Hyper-Parameter Optimization¶
Any LightGBM hyperparameter can be tuned, where the structure of the parameter dictionary needs to be as follows:
- Float/Int sample_type
- {"param_name": ["sample_type", low, high, log]}
- sample_type: str, Type of sampling, e.g., "float" or "int"
- low: int, Lower endpoint of the range of suggested values
- high: int, Upper endpoint of the range of suggested values
- log: bool, Flag to sample the value from the log domain or not
- Example: {"eta": "float", low=1e-5, high=1, log=True]}
- Categorical sample_type
- {"param_name": ["sample_type", ["choice1", "choice2", "choice3", "..."]]}
- sample_type: str, Type of sampling, either "categorical"
- choice1, choice2, choice3, ...: str, Possible choices for the parameter
- Example: {"boosting": ["categorical", ["gbdt", "dart"]]}
- For parameters without tunable choice (this is needed if tree_method = "gpu_hist" and gpu_id needs to be specified)
- {"param_name": ["none", [value]]},
- param_name: str, Name of the parameter
- value: int, Value of the parameter
- Example: {"gpu_id": ["none", [0]]}param_dict = {
"eta": ["float", {"low": 1e-5, "high": 1, "log": True}],
"max_depth": ["int", {"low": 1, "high": 10, "log": False}],
"min_gain_to_split": ["float", {"low": 1e-8, "high": 40, "log": True}],
"min_sum_hessian_in_leaf": ["float", {"low": 1e-8, "high": 500, "log": True}],
"subsample": ["float", {"low": 0.2, "high": 1.0, "log": False}],
"feature_fraction": ["float", {"low": 0.2, "high": 1.0, "log": False}],
"boosting": ["categorical", ["gbdt"]],
}
np.random.seed(123)
opt_param = lgblss.hyper_opt(param_dict,
dtrain,
num_boost_round=100, # Number of boosting iterations.
nfold=5, # Number of cv-folds.
early_stopping_rounds=20, # Number of early-stopping rounds
max_minutes=60, # Time budget in minutes, i.e., stop study after the given number of minutes.
n_trials=20, # The number of trials. If this argument is set to None, there is no limitation on the number of trials.
silence=True, # Controls the verbosity of the trail, i.e., user can silence the outputs of the trail.
seed=123, # Seed used to generate cv-folds.
hp_seed=None # Seed for random number generator used in the Bayesian hyperparameter search.
)
0%| | 0/20 [00:00<?, ?it/s]
Hyper-Parameter Optimization successfully finished.
Number of finished trials: 20
Best trial:
Value: -177.13368962158688
Params:
eta: 0.013216124285390762
max_depth: 10
min_gain_to_split: 2.3995429964658155e-08
min_sum_hessian_in_leaf: 75.94605936994567
subsample: 0.20049396237050426
feature_fraction: 0.7536825284855249
boosting: gbdt
opt_rounds: 100
Model Training¶
np.random.seed(123)
opt_params = opt_param.copy()
n_rounds = opt_params["opt_rounds"]
del opt_params["opt_rounds"]
# Train Model with optimized hyperparameters
lgblss.train(opt_params,
dtrain,
num_boost_round=n_rounds,
)
Prediction¶
# Set seed for reproducibility
torch.manual_seed(123)
# Number of samples to draw from predicted distribution
n_samples = y_test.shape[0]
quant_sel = [0.05, 0.95] # Quantiles to calculate from predicted distribution
# Sample from predicted distribution
pred_samples = lgblss.predict(X_test,
pred_type="samples",
n_samples=n_samples,
seed=123)
# Calculate quantiles from predicted distribution
pred_quantiles = lgblss.predict(X_test,
pred_type="quantiles",
n_samples=n_samples,
quantiles=quant_sel)
# Returns predicted distributional parameters
pred_params = lgblss.predict(X_test,
pred_type="parameters")
pred_samples.head()
| y_sample0 | y_sample1 | y_sample2 | y_sample3 | y_sample4 | y_sample5 | y_sample6 | y_sample7 | y_sample8 | y_sample9 | ... | y_sample4118 | y_sample4119 | y_sample4120 | y_sample4121 | y_sample4122 | y_sample4123 | y_sample4124 | y_sample4125 | y_sample4126 | y_sample4127 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2.183442 | 1.743304 | 2.216470 | 1.648098 | 1.507569 | 2.085007 | 1.849130 | 1.713528 | 2.646151 | 1.948517 | ... | 2.056915 | 1.473761 | 1.776685 | 2.372680 | 1.886026 | 2.179646 | 1.874402 | 1.914331 | 2.328575 | 5.000010 |
| 1 | 0.929630 | 0.864679 | 0.786885 | 0.947967 | 1.161466 | 0.800401 | 0.866021 | 1.139378 | 0.996050 | 2.367984 | ... | 0.796424 | 0.631778 | 0.832294 | 1.434881 | 1.046734 | 0.739934 | 0.933194 | 0.945460 | 0.846469 | 1.022823 |
| 2 | 1.670022 | 1.420544 | 1.394724 | 1.287219 | 1.562551 | 1.532210 | 1.351166 | 1.282929 | 1.370430 | 1.379523 | ... | 1.517579 | 1.609070 | 1.263225 | 1.447542 | 1.422559 | 1.812555 | 1.506740 | 1.657970 | 1.837240 | 1.364948 |
| 3 | 1.648252 | 5.000010 | 1.913860 | 1.524939 | 1.235044 | 1.695537 | 1.822447 | 5.000010 | 1.594498 | 1.504216 | ... | 1.976638 | 1.827072 | 1.785533 | 1.455808 | 1.893041 | 1.747105 | 1.818361 | 1.555387 | 1.533211 | 2.001599 |
| 4 | 3.372061 | 2.330062 | 3.898244 | 2.260443 | 1.889219 | 4.780472 | 3.087396 | 1.930116 | 1.833662 | 2.483598 | ... | 5.000010 | 1.515394 | 2.842309 | 4.024762 | 3.275737 | 3.986492 | 2.120926 | 4.455951 | 4.522376 | 4.789488 |
5 rows × 4128 columns
pred_quantiles.head()
| quant_0.05 | quant_0.95 | |
|---|---|---|
| 0 | 1.573016 | 2.779724 |
| 1 | 0.658904 | 1.298734 |
| 2 | 1.122872 | 1.713133 |
| 3 | 1.417880 | 4.537072 |
| 4 | 1.771191 | 5.000010 |
pred_params.head()
| loc_1 | loc_2 | loc_3 | loc_4 | scale_1 | scale_2 | scale_3 | scale_4 | mix_prob_1 | mix_prob_2 | mix_prob_3 | mix_prob_4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5.00001 | 1.678897 | 2.053436 | 2.501868 | 0.000001 | 0.163506 | 0.227133 | 0.428317 | 0.012478 | 0.140148 | 0.698507 | 0.148867 |
| 1 | 5.00001 | 0.880190 | 0.931146 | 1.836034 | 0.000001 | 0.096553 | 0.227794 | 0.718976 | 0.002728 | 0.606532 | 0.348535 | 0.042204 |
| 2 | 5.00001 | 1.375407 | 1.457845 | 1.915358 | 0.000001 | 0.152090 | 0.198093 | 0.601602 | 0.001360 | 0.766224 | 0.204061 | 0.028355 |
| 3 | 5.00001 | 1.660305 | 1.861541 | 2.109918 | 0.000001 | 0.186978 | 0.192834 | 0.445636 | 0.057176 | 0.266268 | 0.341051 | 0.335504 |
| 4 | 5.00001 | 2.177890 | 3.303763 | 3.737532 | 0.000001 | 0.360660 | 0.799386 | 0.648436 | 0.039917 | 0.320158 | 0.273619 | 0.366306 |
SHAP Interpretability¶
# Partial Dependence Plot
shap_df = pd.DataFrame(X_train, columns=feature_names)
lgblss.plot(shap_df,
parameter="mix_prob_1",
feature=feature_names[0],
plot_type="Partial_Dependence")


# Feature Importance
lgblss.plot(shap_df,
parameter="mix_prob_1",
plot_type="Feature_Importance")

Density Plots¶
In the following, we plot the actual and a subsample of the predicted denstites.
n_subset = 10
pred_df = pred_samples.iloc[:,0:n_subset]
pred_df.columns=[f"Sample {i+1}" for i in range(n_subset)]
actual_df = pd.DataFrame(y_test.reshape(-1,), columns = ["Actual"])
plot_df = pd.concat([pred_df, actual_df], axis=1)
linestyles = ["--" for _ in range(n_subset)] + ["solid"]
linewidths = [1 for _ in range(n_subset)] + [2.5]
plt.figure(figsize=figure_size)
for idx, col in enumerate(plot_df.columns):
sns.kdeplot(plot_df[col], linestyle=linestyles[idx], lw=linewidths[idx], label=col)
plt.legend()
plt.title("Actual vs. Predicted Densities", fontsize=20)
plt.gca().set_xlabel("y")
plt.gca().set_ylabel("f(y)")
plt.show()

Component Distributions¶
We can also plot each Gaussian component distribution.
# Extract predicted parameters
mix_params = torch.split(torch.tensor(pred_params.values[0,:]).reshape(1,-1), lgblss.dist.M, dim=1)
mix_params[1][0][0] = mix_params[1][0][0] + torch.tensor(0.1) # increase the std of the first density for plotting reasons
# Create Mixture-Distribution
torch.manual_seed(123)
mix_dist = lgblss.dist.create_mixture_distribution(mix_params)
gaus_dist = mix_dist._component_distribution
gaus_samples = pd.DataFrame(
gaus_dist.sample((y_test.shape[0],)).reshape(-1, lgblss.dist.M).numpy(),
columns = [f"Density {i+1}" for i in range(lgblss.dist.M)]
)
# Plot
plt.figure(figsize=figure_size)
sns.kdeplot(gaus_samples, lw=2.5)
plt.title("Gaussian-Mixture Component Distributions", fontsize=20)
plt.show()

Actual vs. Predicted¶
Since we predict the entire conditional distribution, we can overlay the point predictions with predicted densities, from which we can also derive quantiles of interest.
y_pred = []
n_examples = 8
q_sel = [0.05, 0.95]
y_sel=0
samples_arr = pred_samples.values.reshape(-1,n_samples)
for i in range(n_examples):
y_samples = pd.DataFrame(samples_arr[i,:].reshape(-1,1), columns=["PREDICT_DENSITY"])
y_samples["PREDICT_POINT"] = y_samples["PREDICT_DENSITY"].mean()
y_samples["PREDICT_Q05"] = y_samples["PREDICT_DENSITY"].quantile(q=q_sel[0])
y_samples["PREDICT_Q95"] = y_samples["PREDICT_DENSITY"].quantile(q=q_sel[1])
y_samples["ACTUAL"] = y_test[i]
y_samples["obs"]= f"Obervation {i+1}"
y_pred.append(y_samples)
pred_df = pd.melt(pd.concat(y_pred, axis=0), id_vars="obs")
pred_df["obs"] = pd.Categorical(pred_df["obs"], categories=[f"Obervation {i+1}" for i in range(n_examples)])
df_actual, df_pred_dens, df_pred_point, df_q05, df_q95 = [x for _, x in pred_df.groupby("variable")]
plot_pred = (
ggplot(pred_df,
aes(color="variable")) +
stat_density(df_pred_dens,
aes(x="value"),
size=1.1) +
geom_point(df_pred_point,
aes(x="value",
y=0),
size=1.4) +
geom_point(df_actual,
aes(x="value",
y=0),
size=1.4) +
geom_vline(df_q05,
aes(xintercept="value",
fill="variable",
color="variable"),
linetype="dashed",
size=1.1) +
geom_vline(df_q95,
aes(xintercept="value",
fill="variable",
color="variable"),
linetype="dashed",
size=1.1) +
facet_wrap("obs",
scales="free",
ncol=4) +
labs(title="Predicted vs. Actual \n",
x = "") +
theme_bw(base_size=15) +
theme(plot_title = element_text(hjust = 0.5)) +
scale_fill_brewer(type="qual", palette="Dark2") +
theme(legend_position="bottom",
legend_title = element_blank()
)
)
print(plot_pred)
